Dust the Blinds:
Abstract
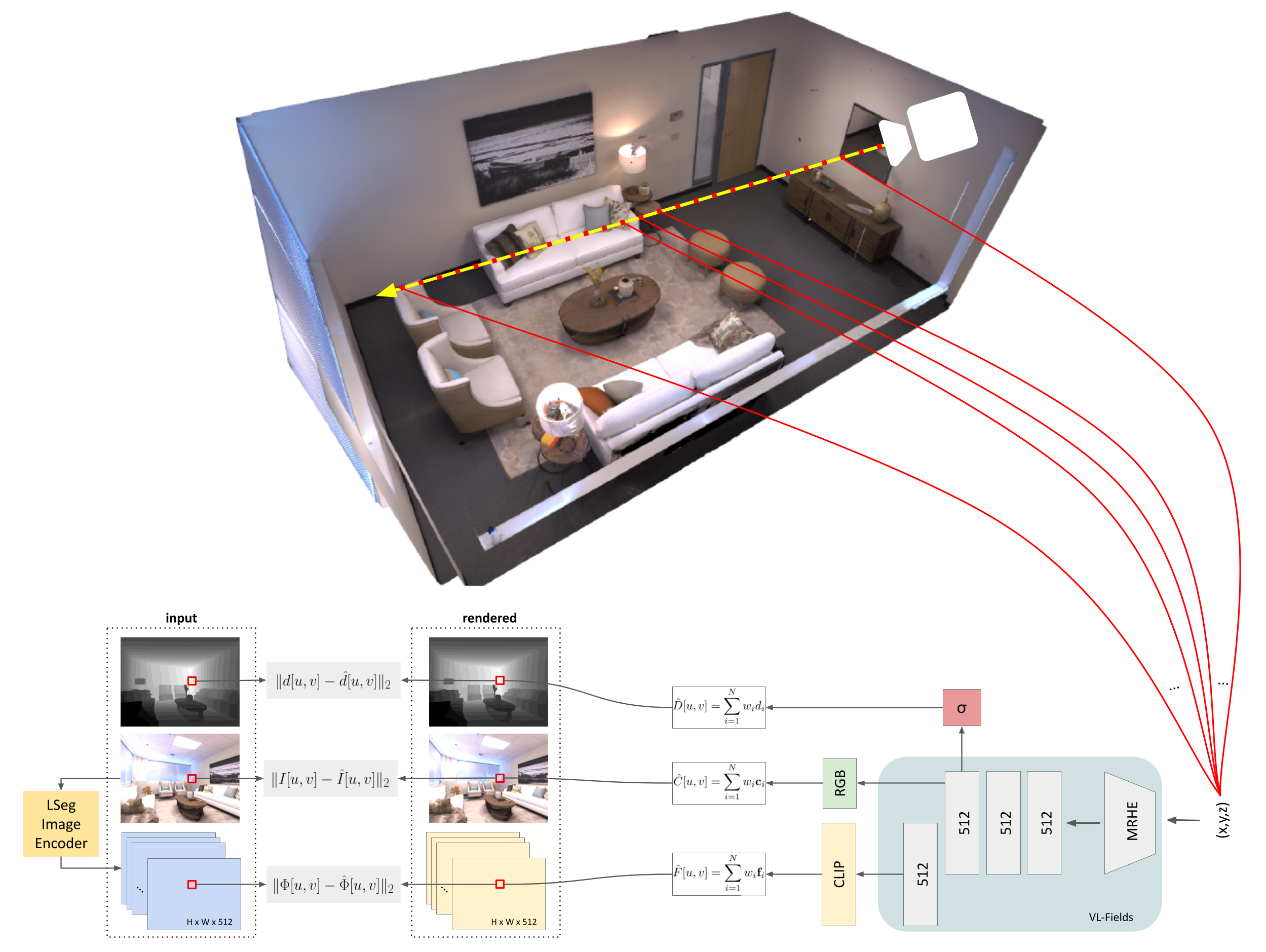
We present Visual-Language Fields (VL-Fields), a neural implicit spatial representation that enables open-vocabulary semantic queries. Our model encodes and fuses the geometry of a scene with vision-language trained latent features by distilling information from a language-driven segmentation model. VL-Fields is trained without requiring any prior knowledge of the scene object classes, which makes it a promising representation for the field of robotics. Our model outperformed the similar CLIP-Fields model in the task of semantic segmentation by almost 10%.
Open-Vocabulary Queries